Transformer 연습 두번째 포스팅이다.
첫번째 포스팅을 9월 21일에 작성했던데...... 어느새 한달이 훌쩍 지나버렸다.
그때 당시에는 코드 작성 업무가 마무리되는 단계였어서
좀 한가할 줄 알고.. 글 써보려한건데
어림도없지 문서작업으로 너무 바빴어서 블로그 할 시간이 없었다 ㅠㅠ
다시 잠깐.. 이번주에는 짬이 날것 같아서!
튜토리얼을 실행해보고 또 시간이 되면 실제 데이터로 실습해보겠다.
실제 데이터를 이용해서 바로 해보려 했으나.. 어떻게 사용해야 하는지 감이 안와서
튜토리얼부터 찾아서 해보기로 했다.
1. 튜토리얼 코드 확인하기
https://github.com/huggingface/transformers
GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, a...
github.com
내가 참고하고 있는 이 코드의 Readme를 보니,

튜토리얼을 진행할 수 있는 링크가 있다!
https://huggingface.co/docs/transformers/task_summary
여기 사이트로 연결되는데,
어떤 분석을 할건지에 따라 여러가지 튜토리얼들이 작성되어있다.
2. 예제 코드 확인하기
위 링크를 타고 가서, 먼저 이미지 관련한 분석부터 해보자.
Image classification을 실행해보자.
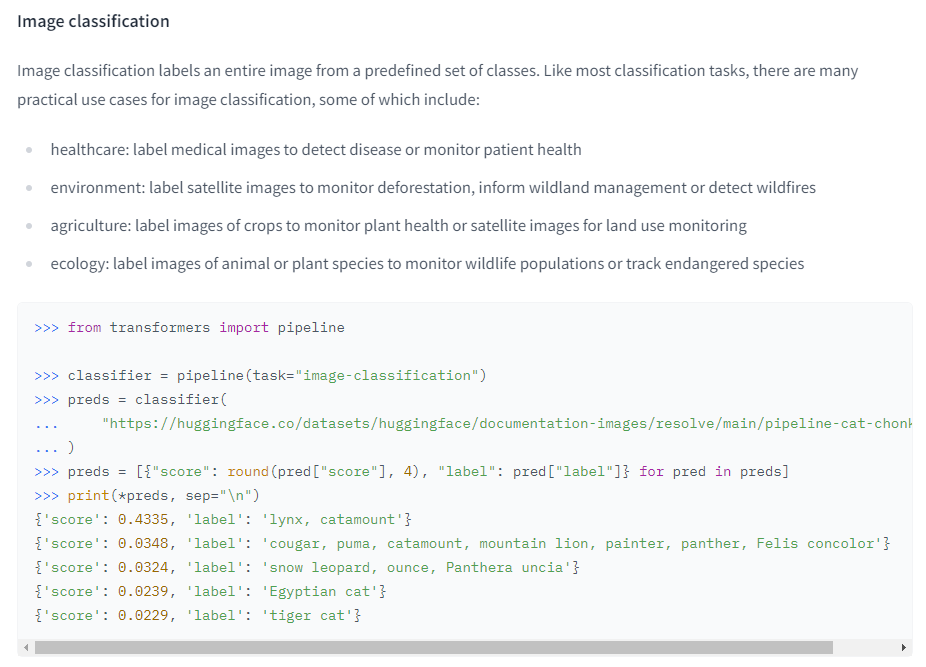
친절하게 실행 방법과 결과가 나와있다.
코드부분만 보면 아래와 같다.
from transformers import pipeline
classifier = pipeline(task="image-classification")
preds = classifier(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg")
preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
print(*preds, sep="\n")
3. 코드 실행하기
Visual Studio Code를 켜고 아무 폴더에 jupyter 파일을 만들어준다.
그리고 위 코드를 복붙해준다.

코드를 돌리기 전에, 저번에 만들어 줬던 가상환경에서 코드를 실행할 수 있도록 해줄것이다.
Ctrl + Shift + P를 눌러 Python: Select interpreter를 클릭하고
원하는 python 환경을 선택해주자.

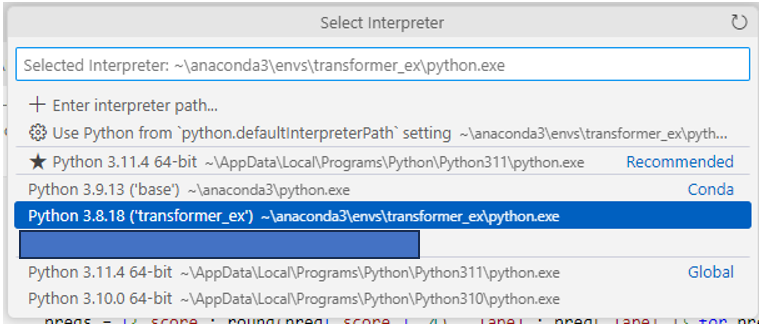
나의 경우 저번 게시글에서 python 버전 3.8, transformer_ex라는 이름으로 가상환경을 만들었고
그래서 해당 가상환경을 선택해 주었다.
인터프리터를 잘 선택해 주었으면, 이제 코드를 실행해주면 된다.
만약 ipykernel을 설치하라는 경고창이 나오면 확인을 눌러줘서 ipykernel을 설치해준다.
만약 해당 경고 없이 실행이 안되면, pip를 이용해 별도로 설치를 해보길 바란다.
pip install ipykernel
나는 별다른 오류 없이 확인 버튼 클릭 후 바로 코드가 실행되었다.
4. 결과 확인하기

예시 코드처럼 이미지를 잘 분류한 모습을 볼 수 있다.
"No model ~ recommended."에 대한 내용은 대충 번역해보면
자동으로 vit-base-patch16-224 모델을 사용했으나 사전 학습된 모델을 사용할 때에는 그 모델의 이름을 명시하라는 내용 같다.
아마 코드 업데이트를 하면서 변경된 사항을 튜토리얼에는 반영하지 않아서 생긴 이슈인것 같다.
동작하는데 큰 문제가 되지는 않지만, pipeline에서 사전 모델 이름을 명시해서 사용하는 방법은 다음과 같다.
from transformers import pipeline
classifier = pipeline(task="image-classification", model="google/vit-base-patch16-224")
preds = classifier(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg")
preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
print(*preds, sep="\n")
경고 메세지에서 나온 google/vit-base-patch16-224를 그대로 pipeline의 파라미터로 넣어주었다.
다른 사전 학습된 모델을 사용하려면 저렇게 model = "~~" 파라미터를 이용해서 넣어주면 된다.
튜토리얼 자체는 어떤 모델을 사용하냐에 따라 크게 다르지 않아서 일단 튜토리얼은 이렇게 마친다.
다음 포스팅에서는 별도의 데이터셋을 이용하여 Transformer을 이용한 수치예측을 해보려고 한다.
꼭! 조만간 다시 업로드 할 수 있기를..
'IT > Transformer 공부' 카테고리의 다른 글
| 이론) Transformer 차근차근 이해하기(2) - Input Embedding (1) | 2024.12.23 |
|---|---|
| 이론) Transformer 차근차근 이해하기 (1) - 구조 익히기 (2) | 2024.12.18 |
| [python] Transformer 연습해보기(4, 종료) - 실패 원인 복기 (0) | 2024.12.18 |
| [python] Transformer 연습해보기(3) - 실제 데이터 적용해보기 (Time Series) Part.1 (1) | 2023.11.14 |
| [python] Transformer 연습해보기(1) - 가상환경 설정 (4) | 2023.09.21 |


