Transformer 연습 세번째 포스팅이다!
요즘 여유가 생겨서 다시 이어서 연습해보려고 한다.
https://dongdu-blog.tistory.com/9
[python] Transformer 연습해보기(2) - Tutorial 따라해보기
Transformer 연습 두번째 포스팅이다. 첫번째 포스팅을 9월 21일에 작성했던데...... 어느새 한달이 훌쩍 지나버렸다. 그때 당시에는 코드 작성 업무가 마무리되는 단계였어서 좀 한가할 줄 알고.. 글
dongdu-blog.tistory.com
저번 게시글에서는 hugging face의 홈페이지에 있는 튜토리얼을 따라해 봤었다.
이번에는 내 데이터를 가지고 직접 구현해보는 시간을 갖겠다!
1. 데이터 준비하기
간단한 시계열 예측을 해보기 위해서, 기온 예측을 해보기로 했다.
https://data.kma.go.kr/data/grnd/selectAsosRltmList.do?pgmNo=36
기상자료개방포털[데이터:기상관측:지상:종관기상관측(ASOS):자료]
Home 데이터기상관측지상종관기상관측(ASOS) 종관기상관측(ASOS) --> 자바스크립트가 비활성 되었습니다. 해당 기능은 자바스크립트에서 활성상태에서 사용가능합니다. 종관기상관측이란 종관
data.kma.go.kr
데이터는 기상청의 기상자료개방포털에서 다운받아 사용했다.
해당 홈페이지에서 장기간의 데이터를 다운받으려면 회원가입을 해야한다.
(비회원으로는 row 10개의 작은 데이터만 다운 가능함)
나는 2022년 1월 1일~ 2022년 12월 31일 (1년간) 서울의 기온데이터를 이용했다.
테스트 데이터로는 2023년 1월 1일~ 2023년 1월 31 데이터를 준비해줄거다.

원하는 조건을 골라 걸어주고 csv로 다운로드한다.
기온에 영향을 주는 계절 정보나 강수량 등 다른 데이터와 함께 사용하면 성능이 더 좋게 나올거같은데
일단 사용법을 익히는 느낌으로? 일단 간단하게 진짜 모델만 돌려본다는 느낌으로만 진행하려고한다.
2. Transformer 시계열 예측 예시 살펴보기(진짜 보기만 함)
이제 어떤 코드를 통해 시계열 예측을 할 수 있는지 확인해봐야한다.
https://huggingface.co/docs/transformers/model_doc/time_series_transformer
Time Series Transformer
Although the recipe for forward pass needs to be defined within this function, one should call the Module instance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
huggingface.co
여기 사이트를 참고했다.
차례대로 살펴보자.
-TimeSeriesTransformerModel 단계를 살펴봐보자. (일단은 참고용으로 가져왔다.)
from huggingface_hub import hf_hub_download
import torch
from transformers import TimeSeriesTransformerModel
file = hf_hub_download(
repo_id="hf-internal-testing/tourism-monthly-batch", filename="train-batch.pt", repo_type="dataset"
)
batch = torch.load(file)
model = TimeSeriesTransformerModel.from_pretrained("huggingface/time-series-transformer-tourism-monthly")
# during training, one provides both past and future values
# as well as possible additional features
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"],
static_real_features=batch["static_real_features"],
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
)
last_hidden_state = outputs.last_hidden_state
이런식으로 작성이 되어있는데, 지난 게시글에서 모델을 정하고 데이터를 정해주는 부분이 있었다.
이전 게시글은 이미지 classifier라서 지금이랑 좀 다르지만, 그때 당시 model명을 넣어주고, http 링크로 이미지 데이터를 넣어줬었다.
여기에서는 그 부분과 매칭되는 부분이 hf_hub_download랑 TimeSeriesTransformerModel.from_pretrained 부분인거 같다.(뇌피셜)
목표는
데이터 -> 내 pc에 있는 데이터
모델 ->시계열에 적절한 모델 혹은 기온예측이 잘 되도록 학습된 모델사용
이렇게 적용해보는 것이다.
먼저 데이터부터 가져와보자.
3. 데이터셋 불러오기
모델에 사용하기에 앞서, 모델에 사용할 수 있도록 간단하게 전처리를 단계를 거칠것이다.
나는 간단하게 해볼거라서, 날짜와 기온를 이용할 것이다.
날짜를 datetime형식으로 변환해주고, 필요없는 컬럼들을 날리자.
import pandas as pd
data = pd.read_csv("weather_data_2022.csv", encoding='CP949')
# display(data)
data['일시'] = pd.to_datetime(data['일시'])
data = data[['일시', '기온(°C)']]
data.columns = ['datetime', 'temperature']
# display(data)
data.to_csv('weather_data_preprocessed_2022.csv', index=False)

컬럼명은 오류 방지를 위해서 영어로 바꿨다.
일단은 요대로 활용할 수 있도록 csv로 저장했다.
테스트 데이터도 준비 했는데, 2023년의 1월 한달간 데이터를 테스트로 사용할 것이다.
위 과정과 똑같이 진행해서 준비해주자.
4. 모델에 사용할 수 있도록 내 데이터셋 변환하기
열심히 구글링 해봤는데 생각보다 전반적으로 게시글 수준이 높아져서 어떻게 해야할 지 좀 갈팡질팡 하다가
아래 위키독스를 발견했다.
1. 만일 자신의 데이터셋이 허브에 없다면?
우리는 이제 [Hugging Face Hub](https://huggingface.co/datasets)를 사용하여 데이터셋을 다운로드하는 방법을 알고 있지만, 일반적으로는 노트…
wikidocs.net
구글에 use huggingface my dataset, huggingface datasets 사용법.. 등으로 검색해서 찾았다.
load_dataset을 이용하여 데이터를 가져오는 모습이다. 이 라이브러리도 huggingface에서 만든 모양이다.
파일 형식에 맞추어 따라해보자.
ctrl+shift+p로 초반에 만들었던 anaconda 가상환경을 선택해주고,
# 라이브러리 설치
pip install datasets
from datasets import load_dataset
#train용, test용 데이터 준비
data_files = {'weather_data_preprocessed_2022.csv', 'weather_data_preprocessed_2023_01.csv'}
my_data = load_dataset("csv", data_files=data_files)
#파일 하나로만 하는 경우
my_data = load_dataset("csv", data_files="weather_data_preprocessed_2022.csv")이렇게 dataset을 만들어주면
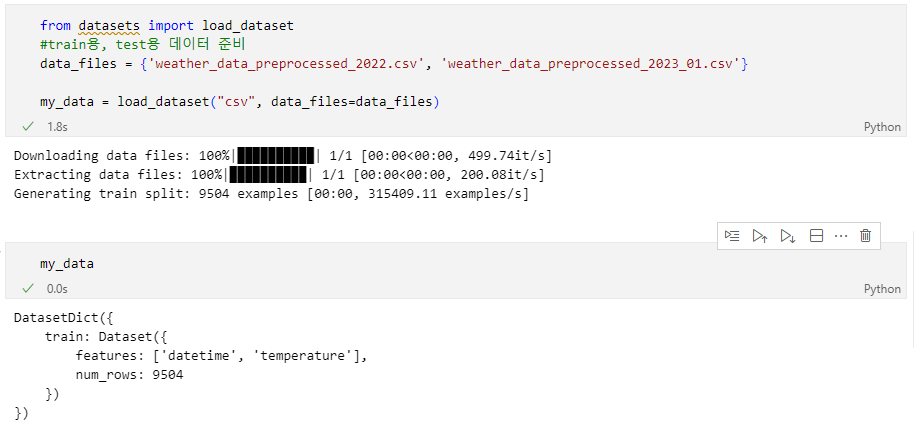
이렇게 잘 나오는 것을 확인 할 수 있다.
<DatasetGenerationError 에러나는 경우>
+)load_dataset 오류나는 경우
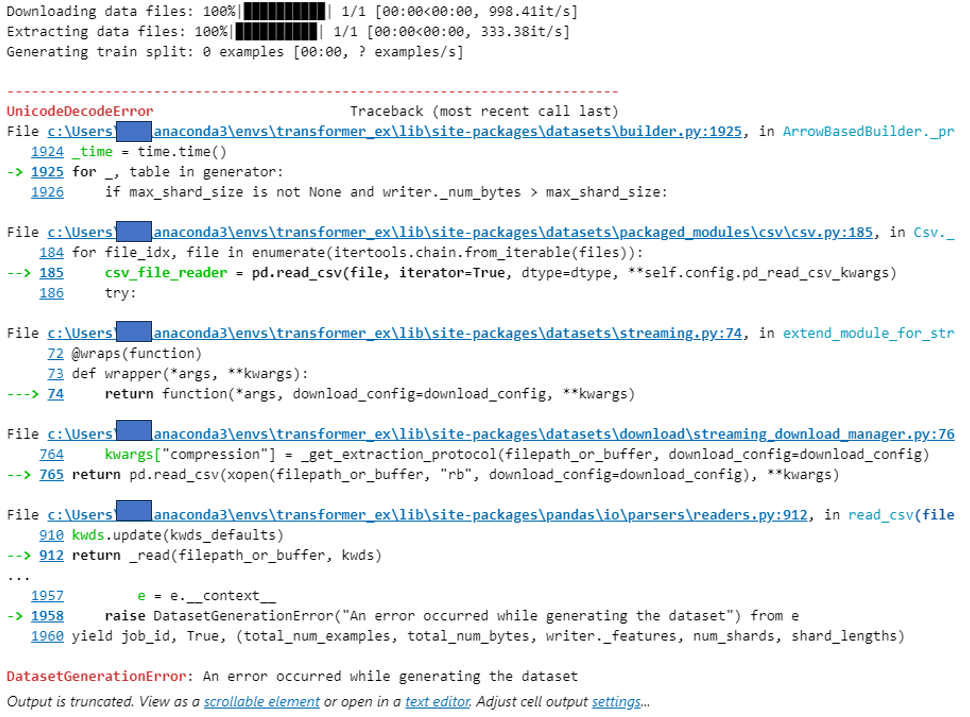
나는 초반에 이런 오류가 났었는데 잘 보면 UnicodeDecodeError라며 Generation Error가 났다고 되어있는데,
데이터 열 이름 및 데이터가 한글로 되어있어서 영어로 바꿔줬더니 해결됐다.
5. 모델링 준비
이제 사전 학습된 모델을 찾아보자.
Models - Hugging Face
huggingface.co
여기 사이트에서 적당한 모델을 선택 할 수 있다.
그런데, pretrained model을 사용하려면 데이터의 구조가 같아야하지 않을까?
다시 생각해보니까 내가 원하는 데이터 구조와 동일하게 학습된 모델이 있을 확률이 낮을 것 같았다.
그래서 대충 좀 찾아봤는데,역시나 내 데이터에 적합한 모델은 없었다.
(그래서 pretrained model 사용하는 예제들의 경우 데이터도 함께 받아오는구나...쩝)
그래서 직접 모델 학습하는 방법을 찾아봤다.
구글링 결과 chat gpt도 그렇고 다른 게시글도 그렇고 일단 config를 만드는 것을 확인했다.
https://huggingface.co/docs/transformers/model_doc/time_series_transformer
Time Series Transformer
Although the recipe for forward pass needs to be defined within this function, one should call the Module instance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
huggingface.co
다시 위 링크의 앞부분을 읽어봤다.
초반부에 config 관련 내용이 있었다.

잘 모르겠어서 python으로 help(TimeSeriesTransformerConfig)를 쳐서 사용법을 확인해 보니
파라미터들이 엄청 많은데 prediction_length 외에는 전부 다 optional인걸 확인했다.


prediction_length 의 경우 아무래도 시계열이다보니 12로 예시를 든 것 같다.
나도 12로 하면 될 것 같아 동일하게 작성했다.
from transformers import TimeSeriesTransformerConfig, TimeSeriesTransformerModel
help(TimeSeriesTransformerConfig)
# Initializing a Time Series Transformer configuration with 12 time steps for prediction
configuration = TimeSeriesTransformerConfig(prediction_length=12)
# Randomly initializing a model (with random weights) from the configuration
model = TimeSeriesTransformerModel(configuration)
# Accessing the model configuration
configuration = model.config
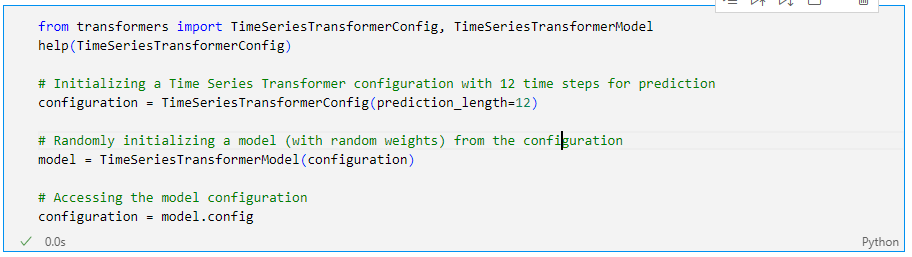
이제 모델 생성은 됐고 학습만 해주면 될거같다.
내가 이걸 다 하고 정리하는게 아니라
검색, 코딩을 하면서 글까지 쓰는 중이라 생각보다 시간이 오래걸렸다.
원래 학습된 모델을 사용해서 바로 예측하려고 했는데 모델을 직접만들고 학습까지 해야하니
생각과 다르게 양이 좀 늘어나버린 느낌
학습 및 예측 부분은 다음 게시글에서 마저 진행해보도록 하겠다.
다음 게시글 안에는 꼭 시계열 예시 마무리 짓고싶다!!
'IT > Transformer 공부' 카테고리의 다른 글
| 이론) Transformer 차근차근 이해하기(2) - Input Embedding (1) | 2024.12.23 |
|---|---|
| 이론) Transformer 차근차근 이해하기 (1) - 구조 익히기 (2) | 2024.12.18 |
| [python] Transformer 연습해보기(4, 종료) - 실패 원인 복기 (0) | 2024.12.18 |
| [python] Transformer 연습해보기(2) - Tutorial 따라해보기 (0) | 2023.10.31 |
| [python] Transformer 연습해보기(1) - 가상환경 설정 (4) | 2023.09.21 |


